Making musical instruments speak using AI
Miloš Švaňa
5 years ago 29.6.2021

Have you ever seen a speaking piano? Pretty cool, right? At profiq, we sometimes take a break from serious business and explore some pretty obscure ideas. A musical instrument able to replicate human speech is one of them. Inspired by YouTube videos and by our friends from the House of Hungarian Music in Budapest, we decided to dive deeper into the science and technology behind speaking instruments. Our mission? To understand how everything works, go beyond just a single instrument, and create an entire “speaking orchestra”.
Our methodology
In order to replicate sound or any other type of signal for that matter, it’s a good idea to get a better understanding of its components. So we started our exploration with a pretty traditional tool: Fourier transform. This technique is used widely in signal processing. The idea is to reconstruct a signal as a combination of multiple sine waves. Each of these waves can have a different frequency and amplitude.
But, how does this help us replicate human speech on an instrument? Different frequencies in a sound wave represent different tones. We can recreate these tones by pressing a specific key on a piano. Fourier transform helps us determine which tones (or frequencies) a certain sound consists of. If we replay this combination on a musical instrument, we should be able to replicate the original sound.
Being a popular choice among data scientists, we chose to implement all our experiments in Python. This turned out to be a good decision, as Python packages provide almost all of the functionality we need.
The only exception was proper support for synthesizing the results on a computer. Unfortunately, real instruments weren’t available, so we needed to find a way of playing the extracted notes in order to evaluate the results. After trying different tools, we settled with fluidsynth. This simple command-line application can take a MIDI file that contains commands for a musical instrument generated in Python, and synthesize a standard WAV recording. And, just as you can select a font when writing a text document, fluidsynth lets you easily choose an instrument from a soundfont. This let us experiment with multiple types of pianos and organs, and also with marimba or drums.
Although the Fourier transform was fun and provided results that at least somewhat resembled the original human voice, we still weren’t fully satisfied. So, we decided to find out if AI, and more specifically, deep learning methods, can be used to select a proper sequence of notes to imitate human speech. And this is where things get interesting.
Transcribing speech to music with deep learning
Deep (machine) learning is a broad field offering many different approaches for solving the difficult tasks we often relate to artificial intelligence, including image recognition, classification of objects, or prediction of future values of some variable. The choice of a proper approach depends strongly on the character of the problem at hand.
Speech and music can be both considered as sequential data. Keeping this in mind, we chose a subcategory of neural networks that can deal exactly with this type of information: Recurrent neural networks (RNNs). Put simply, these networks contain memory cells that can remember previous input. When processing a certain part of recording, RNNs let us use some information about parts that came before.
Training data
As with any machine learning project, we needed to start with some raw data. We decided to use an open source musical collection from Google called MAESTRO. This 120GB dataset contains almost 200 hours of piano performance, together with corresponding MIDI files. These MIDI files provide instructions for both physical instruments and synthesizers on what notes to play in order to replicate the recordings. They are like sheet music for machines.
So, the plan was set—using supervised learning, we wanted to train an RNN that would take raw recording data as input, and then generate a matrix of notes to play at a specific, discrete time period. Such a matrix can then be easily transformed into an actual WAV recording. This process would let us replicate the original recording with a synthesizer on a physical musical instrument.
You might wonder why we chose piano recordings instead of a dataset containing actual human speech. The main reason was that we couldn’t find one. There are many collections of human voice recordings, but none of them are “labeled” with notes that should be played on a musical instrument to replicate the speech. We could of course try different approaches including reinforcement learning. There is a plan for that in the future, but for now we decided to limit the solution to supervised learning.
Using piano recordings also provides a sneak peek into the area of transfer learning, which focuses on reusing machine learning models across multiple domains with little to no changes.
Data preprocessing
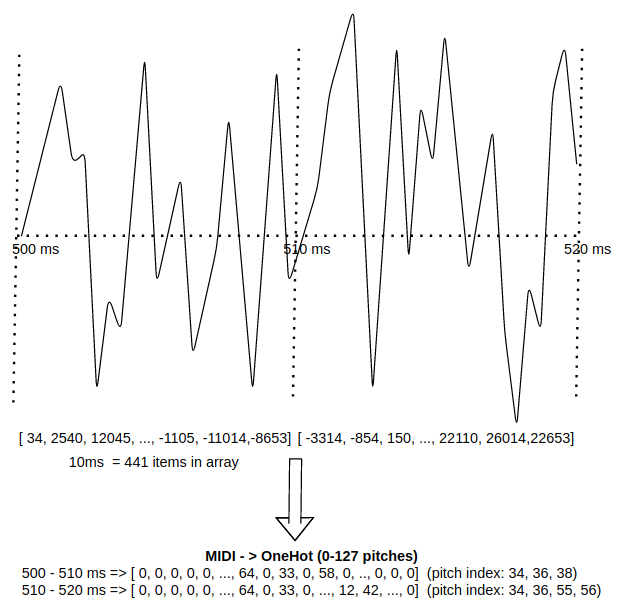
In our experiments, we used only a small portion of the whole MAESTRO dataset. Selected recordings were loaded and further represented as a simple numpy array. This representation is very natural, because WAV files usually contain sound as a simple list of amplitudes in time.
The soundwaves were then split into short chunks of the same length. For our experiments, we set this length to 10ms. The last chunk of recording was padded with zeros to match the length of other chunks. These were then used as an input for our RNN.
As for output, we took the MIDI files contained in the dataset and transformed the MIDI commands into vectors containing velocities (volumes) of notes that are actually played at a given moment. Since only a small portion of all available notes is played at any moment, this vector is sparse.
Parameters and model definition
The most complicated part was estimating the parameters of the neural network. Processing 100ms of sound at once, and using sampling rate 44.1 kHz, the input vector size was 4410. As for output, the network generates a 10×128 matrix, which lets us play a different set of notes every 10 milliseconds.
Between the input and output, our neural network contains 9 hidden layers, including 2 LSTM (Long-short term memory) layers. These layers give us more than 7 million trainable parameters. A network of this size is still considered quite small. The model was implemented in Keras using following code:
model = keras.Sequential() model.add(Input(shape=(1,44100 * len_seq))) model.add(LSTM(256, activation='relu', return_sequences=True)) model.add(BatchNormalization()) model.add(LSTM(512, activation='relu', return_sequences=True)) model.add(Flatten()) model.add(Dense(512, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(256, activation='relu')) model.add(Dense(100 * len_seq * 128)) model.add(Reshape((len_seq * 100, 128))) model.summary()
We trained the model in 20 epochs with batch size set to 32. Validation split was used to monitor interim results during training. As for hardware, we decided to use free computational resources offered by Kaggle and Google Colab. The project is still in a proof-of-concept stage, so it didn’t make much sense to invest in more powerful hardware. We are also aware that in the future, the network should be trained for much longer, and on a much larger portion of the dataset.
Results
So how did our network perform after it was trained? You can use your own ears to judge. We recorded our friend Anke quoting Carl Jung: “The creation of something new is not accomplished by the intellect, but by the play instinct arising from inner necessity. The creative mind plays with the object it loves.” This describes the ideal our Technical Research team strives for quite well.
After we had the recording, we tried to replicate it on a synthesized piano using both fast Fourier transform and our neural network:
After having heard all three recordings ourselves, we would say that the Fourier transform version replicates the original recording a bit better. On the other hand, the RNN output sounds a bit more musical, which might have some artistic value in itself. Given we trained the network on piano recordings, this result makes sense.
Original recording
FFT audio
Neural Network audio
The quality of results is hugely affected by the physical limitations of musical instruments. Most musical instruments are not able to produce a clear sine wave of a certain frequency. This includes the piano. Organ pipes are somewhat clearer but still not perfect. We also cannot play just any frequency on a musical instrument. Their frequency range is limited, and even within this limited range, we can only choose from a relatively small number of predefined (dominant) frequencies; for example, given by available piano keys. Finally, the volume of the tone produced by a musical instrument is not constant and changes over time.
These are exactly the reasons why our end goal is to create an orchestra. Combining multiple instruments might help us overcome at least some of the limitations imposed on physical instruments.
What’s next
During the first few weeks of this research project, we were able to produce preliminary results using two methods: Fourier transform and a simple recurrent neural network. These are still a far cry from what we would consider satisfying.
This showed us that the problem we are facing is solvable but it requires a lot more work. Among other things, we need to investigate alternative methods and neural network architectures. These include reinforcement learning or generative adversarial networks (GANs). There is also an intriguing idea of treating sound as image data. The TensorFlow Magenta team from Google is also developing a model specifically designed for converting piano sounds to notes called onset and frame. Although not quite what we need, their work might be very inspiring and helpful.
The project is now starting to grow outside the scope of our Technical Research team. And we didn’t even start considering multiple instruments. Therefore, a standalone team of experts from different organizations, including profiq, is now being formed to continue what we started. Hopefully, one day this research will bear fruit, and you will be able to hear your own voice played by an orchestra of real physical instruments.


