Presto: Running SQL queries on anything

17 min read27.7.2021

It is not uncommon for companies to use multiple data stores based on different technologies. We can easily imagine an organization using relational databases for transactional data, a NoSQL database such as MongoDB for semi-structured data, and an S3 bucket for large datasets.
When performing analytical tasks, we often need to combine data from all of these sources. Traditionally, this meant gathering everything in one place: a data warehouse or a data lake. This brings a lot of issues; movement of data takes time, and we also need to perform various transformations. At the start of our analysis process, we often have no idea which part of our data is actually valuable. We need to explore and experiment; we don’t know the right structure for the data warehouse right away.
Wouldn’t it be cool if we could instead query the data from all these different sources without moving them around? This is exactly what Presto tries to achieve.
Presto is an open source SQL query engine. It lets you use SQL to get data from different sources, even if a given data source doesn’t natively support SQL. And perhaps most interestingly, you can use standard SQL JOINS to combine data from multiple sources.
In this article, we will show you exactly that. We start by setting up a simple Presto cluster with 2 nodes. Then, we add a few data sources. Starting with the Azure SQL database, our focus will be on examining how Presto compares to direct access in terms of query times. We then switch to AWS S3 and demonstrate how we can easily query large JSON files. Finally, we combine both data sources into one output using SQL JOINS. Let’s dive right in!
Setting up a Presto cluster
One of the benefits of Presto is its distributed architecture—workload can be shared between multiple worker nodes. What exactly each individual does is determined by a so-called
coordinator
.
In our experiments, we used a simple setup with 2 nodes. Each of these nodes is a VM with 2 vCPUs, 8GB of RAM, and running Ubuntu 18.04. To run Presto, we first need to have a JVM installed. On Ubuntu, we simply installed OpenJDK:
$ sudo apt install openjdk-11-jdk-headlessThe Presto launcher script also requires Python. Both Python 2 and Python 3 work just fine, and they often come preinstalled with your favourite Linux distribution. The launcher is looking for the
python
command, but some distributions that use Python 3 by default provide only the
python3
command. This can be solved, for example, by creating a
proper symlink
.
After we resolved all prerequisites, we downloaded the Presto official tarball on both VMs and unpacked it:
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.251/presto-server-0.251.tar.gz
$ tar -xzvf presto-server-0.251.tar.gzBefore we can start the Presto server, we first need to create a few configuration files. Inside the Presto directory, we created a file called
etc/node.properties
with the following content:
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/home/presto/dataWe defined the name of our environment (all nodes in a cluster should have the same environment name) and a unique ID for the node. Finally, we told Presto where it should store all its data.
The second configuration file,
etc/jvm.config
, contains the configuration for our Java virtual machine. We used the following config on both nodes:
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-Djdk.attach.allowAttachSelf=trueThe last configuration file is located at
etc/config.properties
,
and differs slightly between our two nodes. The first node will act both as a worker executing assigned workloads, and as a coordinator responsible for scheduling and providing a monitoring web interface. We also set appropriate memory limits:
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
query.max-memory=12GB
query.max-memory-per-node=6GB
query.max-total-memory-per-node=6GB
discovery-server.enabled=true
discovery.uri=http://[coordinator_node_ip]:8080The second node will only run the worker:
coordinator=false
http-server.http.port=8080
query.max-memory=12GB
query.max-memory-per-node=6GB
query.max-total-memory-per-node=6GB
discovery.uri=http://[coordinator_node_ip]:8080We are done with the basic configuration and can start Presto on both nodes:
$ ./bin/launcher startIf Presto started correctly, there should be a web interface running on port 8080 of the coordinator node:
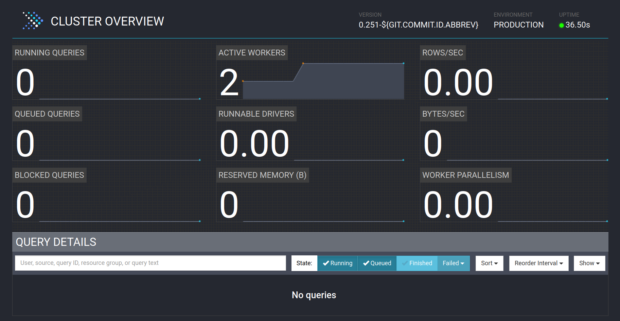
Before we move to adding data sources, we downloaded a simple CLI app to perform SQL queries on our Presto cluster. We will use this app from the coordinator node, so it doesn’t have to be downloaded on the second worker node:
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.251/presto-cli-0.251-executable.jar
$ mv presto-cli-0.251-executable.jar presto
$ chmod a+x prestoWe check that the app works:
$ ./presto
presto> SHOW CATALOGS;
Catalog
-----------
system
(1 row)
presto> exit;In what follows, we accessed Presto using this CLI application. Presto also offers
client libraries
for many programming languages, including Python, Java, or JavaScript.
Connecting to Azure SQL
Data sources in Presto are called
catalogs
. We can add catalogs by creating configuration files in ./etc/catalog/. The content of each configuration file depends on the data source type.
Let’s start by adding a simple Azure SQL database containing information about daily stock prices of publicly traded companies split into two tables. The companies table stores a unique ID of each company, it’s official name, and its stock exchange symbol. The second table, named prices
,
consists of 4 columns: company ID, date, and open and close price. In total, the database contains 2211 companies with a little over 9.4 million price records.
Let’s now define a catalog by creating a file at
./etc/catalog/azurestock.properities
:
connector.name=sqlserver
connection-url=[jdbc_string]
connection-user=[username]
connection-password=[password]The configuration file is easy to understand. We first asked Presto to use the
sqlserver
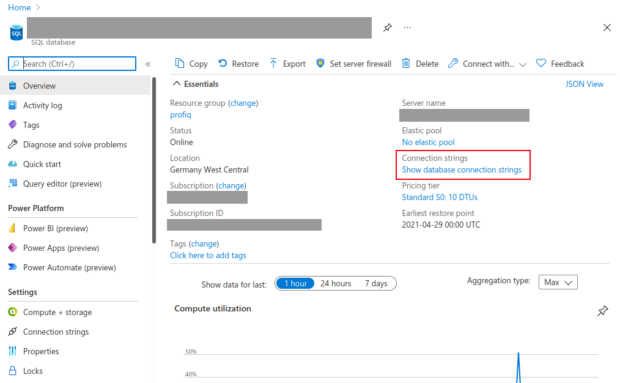
connector, which lets us connect to any Microsoft SQL server database. We provided a JDBC connection string and user credentials. The connection string can be found in the Azure portal:
The file has to be present on both nodes. After the catalog is defined, we restarted Presto by executing
./bin/launcher restart
. Now we are ready to run queries in the Presto CLI tool. We should probably start by checking if Presto indeed registered our new catalog:
./presto
presto> SHOW CATALOGS;
Catalog
------------
azurestock
system
(2 rows)We can see that our catalog is indeed present, and its name matches the name of the configuration file. Let’s see what schemas we can find in the catalog:
presto> SHOW SCHEMAS FROM azurestock;
Schema
--------------------
db_accessadmin
...
information_schema
stockdb
sys
(14 rows)Among all the system schemas, we see one storing our stock price data: stockdb. The
USE
SQL command to tells Presto that we want to work inside this schema:
presto> USE azurestock.stockdb;
USE
presto:stockdb>We are finally ready to select some data. Let’s get first 10000 prices for companies with IDs greater than 10000 and order them by date:
presto:stockdb> SELECT * FROM prices WHERE company_id > 1000 ORDER BY date ASC LIMIT 10000;
company_id | date | open | close
------------+-------------------------+----------+-----------
2805 | 1995-01-02 00:00:00.000 | 45.51 | 45.51
2061 | 1995-01-02 00:00:00.000 | 239.8 | 239.8
...You might notice that we are not using the Microsoft SQL dialect here. Instead, we used the Presto dialect, which is closer to those used by MySQL or PostgreSQL.
We can also perform simple aggregations, such as finding the average price of each stock, and the date range for which we have data:
presto:stockdb> SELECT company_id, AVG(close) AS avg_close, MIN(date) AS min_date, MAX(date) AS max_date FROM stockdb.prices GROUP BY company_id;
company_id | avg_date | min_date | max_date
-----------+----------------------+-------------------------+------------------------
1752 | 27.907111302965017 | 2007-06-22 00:00:00.000 | 2021-04-27 00:00:00.000
1838 | 50.510843540713886 | 1996-12-18 00:00:00.000 | 2021-04-27 00:00:00.000
...Joining multiple tables is possible, too. Let’s get the average stock price for each company again, but this time, we also added the company name, which can be found in the
companies
table:
presto:stockdb> SELECT c.name, AVG(close) AS avg_close FROM stockdb.prices p JOIN companies c ON p.company_id = c.id GROUP BY c.name;
name | avg_close
--------------------------------+----------------------
Charles Schwab Corp | 21.610780258961643
Smith & Nephew | 681.5443440544773
...Let’s talk performance
At this point, you might be wondering how Presto compares with direct access in terms of performance. We wondered too, so we measured query times for the 3
SELECT
queries above both in Presto, and in the Query Editor available in Azure Portal.
The first query with simple filtering and ordering took 35 seconds in Presto. Using direct access, the same query took 206 seconds. Well, this was without any index. Once we created an index on the
date
column, the query time got down to about 100 milliseconds.
As for the second query, with simple aggregation, we actually got better results in Presto: 24 seconds as compared to 35 seconds in the Query Editor. The JOIN query took almost the same time in both cases: 19 seconds on Presto vs 20 seconds through direct access.
We think these results are in line with Presto’s intended use — basic analytical tasks without moving data between multiple sources. This is especially highlighted by the time it took to perform the aggregation query. Given this use case, we decided not to test writing performance.
SQL on S3
The value Presto brings to the table is not that visible when we use it to access data in relational databases. It shines when we use SQL on semi-structured data stored in NoSQL databases, and even in object storages such as S3. Using Presto, you can create a giant data lake on S3 with data stored in a specific format to optimize performance. But in what follows, we will focus on a different use case: how to query data that you already have without changing its structure.
To show how everything works, we will use the
Yelp dataset
hosted on Kaggle. This dataset contains several (line-delimited) JSON files containing information about businesses and users registered on Yelp, as well as reviews of these businesses provided by the users. The largest JSON file in the dataset has a size of almost 6.5 GB, which is still quite modest
Before we can do anything in Presto, we need to set a few things in AWS. First, we need to create a role with access to two services: S3 and AWS Glue. As we are running Presto on EC2, we can simply attach this role to our VMs, and just like that, we solved authentication.
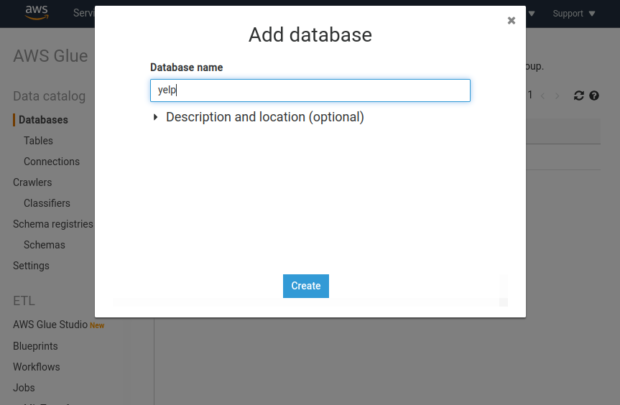
It’s pretty obvious why we need permissions to access S3, but what about AWS Glue? The thing is, that if we want to access S3 data using SQL, we need to describe the structure of this data as if it were a table in a relational database. At the very least, this means defining a table name and listing its columns. We of course need a place to store this metadata. Presto can use Hive Metastore for these purposes. But, since we are already storing our data on S3, we can also use Glue, which is a service designed specifically for this purpose. Configuring Glue is also a bit easier than setting up Hive Metastore. All we need to do is to open the Glue web interface and create a new database. Let’s call it
yelp
:
Assuming we have already created an S3 bucket and also downloaded and unpacked the Yelp dataset to our local machine, we can now upload the data to S3. We can do so using the AWS CLI tool. Let’s upload two files:
businesses.json
and
reviews.json
:
$ aws s3 cp yelp_academic_dataset_business.json s3://[bucket-name]/business.json/1
$ aws s3 cp yelp_academic_dataset_review.json s3://[bucket-name]/reviews.json/1You might have noticed that the location is a bit weird. Presto expects tables on S3 to be directories containing one or multiple partitions with actual data. In our case, we will have just one partition contained inside a file called
1
.
Let’s now define an S3 catalog in Presto by creating a new file at
./etc/catalog/s3yelp.properties
inside the Presto directory on both nodes:
connector.name=hive-hadoop2
hive.metastore=glueIf we are running Presto on an EC2 instance, the configuration is incredibly simple. We only have to define the connector type and tell Presto to use Glue as its metastore. After the catalog is defined, we can restart Presto, open the CLI tool, and check if the catalog is registered:
presto> SHOW CATALOGS;
Catalog
------------
azurestock
s3yelp
system
(3 rows)If we want to define a “table” on our JSON file, we first need to create a new schema. This can be done in the AWS Glue console, but also directly in Presto:
presto> CREATE SCHEMA s3yelp.yelp;
CREATE SCHEMA
presto> SHOW SCHEMAS FROM s3yelp;
Schema
--------------------
information_schema
yelp
(2 rows)We switch to our new schema and finally create tables on the two JSON files:
presto> USE s3yelp.yelp;
USE
presto:yelp> CREATE TABLE businesses (business_id varchar, name varchar, city varchar, review_count int)
WITH (format='JSON', external_location='s3a://[bucket-name]/business.json');
CREATE TABLE
presto:yelp> CREATE TABLE reviews (business_id varchar, user_id varchar, stars int)
WITH (format='JSON',external_location='s3a://[bucket-name]/reviews.json');
CREATE TABLETo understand the table definition, it’s good to have a look at how our JSON files are
structured
. Both files contain a set of JSON objects, one object per line. Each object contains very similar attributes. Names of these attributes correspond to column names of our tables. In our case, we defined only 4 columns in the
businesses
table, but as you can see in the file structure, there are much more than 4 attributes in the JSON file. This is not a problem. Presto lets us use only a small subset of all attributes when we are not interested in the full dataset.
After we define our tables, we can easily perform
SELECT
queries, such as:
presto:yelp> SELECT * FROM businesses WHERE review_count > 100 AND city = 'Dublin' LIMIT 100;
business_id | name | city | review_count
------------------------+-------------------------------------------+--------+--------------
7g_gmU3uW1Iqf2mwMrphUg | LaRosa's Pizza - Dublin | Dublin | 106
6BkTERc6dXeb4A9ShcFozQ | Mr Sushi | Dublin | 148
...We can of course use joins and aggregation functions, too:
presto:yelp> SELECT b.name, AVG(r.stars) AS avg_stars FROM businesses b JOIN reviews r ON b.business_id = r.business_id WHERE b.city = 'Dublin' GROUP BY b.name LIMIT 100;
name | avg_stars
------------------------------------------------+--------------------
Duck Donuts | 4.2682926829268295
Bad Frog Frozen Yogurt | 3.12
...Just to give you an idea about performance, our simple setup with 2 worker nodes needed from 2 to 6 seconds to execute the first query, where we simply selected some data from the
business
table. The second query that joins multiple tables and performs a simple aggregation took from 42 to 52 seconds.
We also need to note that even though Presto doesn’t permanently store the copy of your data anywhere, it still needs to download it to answer your query. This means a lot of traffic. Networking can therefore represent both a bottleneck and an additional cost.
Joins across different data sources
Let’s finally have a look at what we think is one of the coolest features of Presto: joining tables across different data sources. Besides being cool and useful, it’s also very easy. You just need to add correct prefixes to the table names.
To show you how everything works, we defined an additional table on S3. This table structurally matches the
companies
tables from our Azure SQL database, but it is now stored as a line-delimited JSON file. Each object in this file represents one company and has 3 attributes:
id
,
name,
and
symbol.
Using the same procedure as above, we created a table in Presto:
presto> CREATE SCHEMA s3yelp.stocks;
CREATE SCHEMA
presto> USE s3yelp.stocks;
USE
presto:stocks> CREATE TABLE companies (id int, name varchar, symbol varchar)
WITH (format='JSON', external_location='s3a://[bucket-name]/companies.json');If we now prefix table names with correct catalog and schema names, we can easily perform a JOIN query on the
companies
table stored in S3, and the
prices
table in Azure SQL:
presto:stocks> SELECT c.name, AVG(close) AS avg_close FROM azurestock.stockdb.prices p JOIN s3yelp.stocks.companies c ON p.company_id = c.id GROUP BY c.name;
name | avg_close
------------------------------------------------------------------+----------------------
WH Smith PLC | 977.3202206572764
Klepierre SA | 25.50368994984065
...Given the relatively small size of the
companies
table, there was little to no difference in performance compared to having both tables in Azure SQL. The query took about 19 to 20 seconds to execute.
Conclusion
Presto is a great tool if you need to explore all the data your organization has without moving anything around. This is especially useful at the beginning of the data analysis process, when you are not yet sure about what data should be in your data warehouse or data lake, and you need to experiment a bit. We found the ability to join tables across multiple data sources very helpful here. Presto has also helped organizations design a storage solution for data that is accessed infrequently. With Presto, it can be both cheap and easy to use.
Presto is also relatively easy to configure,at least if you decide to use it in combination with AWS and Ubuntu VMs. But if you want to make your life even easier, you can use services such as
Ahana Cloud
or
AWS Athena
, which are both based on Presto, and take most of the low- level configuration stuff from your hands.
On the other hand, we don’t think that Presto is a good replacement for a proper data warehouse or data lake (and it doesn’t claim to be). After initial exploration, performance becomes much more important, and having all data in one place stored in a way that supports your analytics workloads can improve your query times. In this phase, ETL tools such as
Precog
(which even supports Presto as a possible data source) might be just exactly what you need.